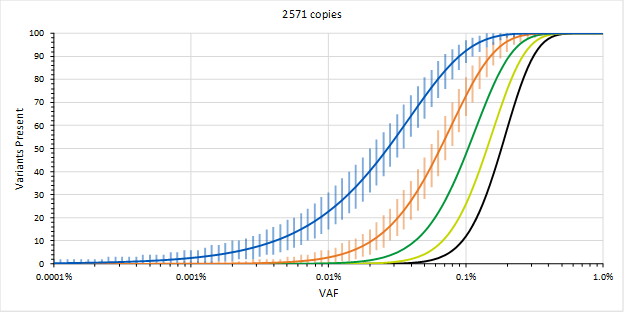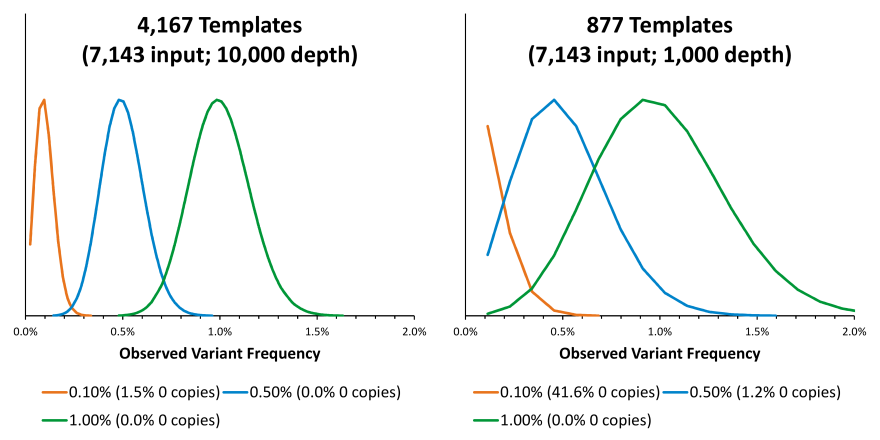
Authors: Yves Konigshofer, PhD; Andrew Anfora, PhD; Omo Clement, PhD; and Krystyna Nahlik, PhD. LGC Clinical Diagnostics. Introduction Liquid biopsy methods developed for circulating tumor DNA (ctDNA) analysis in solid tumors are transforming clinical practice, allowing for non-invasive detection and assessment of earlier stages of disease, monitoring for resistance to therapy, and post-treatment monitoring for minimal residual disease (MRD) and recurrence of cancer. The presence of minimal residual disease may be prognostic in that is has been found to correlate with worse patient outcomes, so early and accurate measurement is crucial. ctDNA-based assays allow for the detection of MRD at earlier time points than standard clinical and imaging surveillance, and could allow for treatment modification based on real-time assessment of the tumor genomic landscape.